
Amazon Athena Icebergテーブルで100パーティションの壁を超えてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。Amazon Athena は、INSERTなど一度に100パーティションを超える書き込みができません。ある時、「あれ、100パーティション超えてるやん」って事があり、それをきっかけに、何ができて何ができないのか、悶々と検証した結果、100パーティションの壁を超える方法をご紹介したいと思います。
先に結論
-
100パーティション超えたい場合は、Icebergテーブルフォーマとを用いて、パーティションの指定を
bucket(100, <指定したいカラム名>)とする。 -
bucket(100, <指定したいカラム名>)は、ハッシュに基づき100のパーティションに分類されるため、パーティション内ではスキャンが発生する -
この方法を使用すると処理時間が長くなる傾向があり、バーティション数によっては、100パーティションの制限とは異なる理由で、エラーになる可能性があります。
Amazon Athena 100パーティションの壁とは
CTAS および INSERT INTO ステートメントで作成できるパーティションの最大数は 100 です。
そして、AWSの公式のワークアラウンド、一度に書き込みするパーティションを100を超えないようにクエリを分割して実行する方法です。
dbt (data build tool)からAmazon AthenaのDBアダプターdbt-athenaでは、100パーティションを超える書き込みがあった場合に分割してクエリを実行するように実装されています。
※ dbt (data build tool)とは、データウェアハウス内のデータ変換を効率化するためのツールです。
検証しようと思ったきっかけ
当時、Athena Engine EngineV2だとエラーでした、Athena Engine EngineV3だと100パーティションを超えているのに正常になる。ここが疑問のスタートラインでした。
create database iceberg_labo;
-- DROP TABLE iceberg_labo.test;
CREATE TABLE iceberg_labo.test (
id int,
data string)
PARTITIONED BY (bucket(16,id))
LOCATION 's3://cm-datalake-20241026/test1/'
TBLPROPERTIES (
'table_type'='ICEBERG'
);
INSERT INTO iceberg_labo.test
VALUES (1,'1'), (2,'2'), (3,'3'), (4,'4'), (5,'5'), (6,'6'), (7,'7'), (8,'8'), (9,'9'), (10,'10'), (11,'11'), (12,'12'), (13,'13'), (14,'14'), (15,'15'), (16,'16'), (17,'17'), (18,'18'), (19,'19'), (20,'20'), (21,'21'), (22,'22'), (23,'23'), (24,'24'), (25,'25'), (26,'26'), (27,'27'), (28,'28'), (29,'29'), (30,'30'), (31,'31'), (32,'32'), (33,'33'), (34,'34'), (35,'35'), (36,'36'), (37,'37'), (38,'38'), (39,'39'), (40,'40'), (41,'41'), (42,'42'), (43,'43'), (44,'44'), (45,'45'), (46,'46'), (47,'47'), (48,'48'), (49,'49'), (50,'50'), (51,'51'), (52,'52'), (53,'53'), (54,'54'), (55,'55'), (56,'56'), (57,'57'), (58,'58'), (59,'59'), (60,'60'), (61,'61'), (62,'62'), (63,'63'), (64,'64'), (65,'65'), (66,'66'), (67,'67'), (68,'68'), (69,'69'), (70,'70'), (71,'71'), (72,'72'), (73,'73'), (74,'74'), (75,'75'), (76,'76'), (77,'77'), (78,'78'), (79,'79'), (80,'80'), (81,'81'), (82,'82'), (83,'83'), (84,'84'), (85,'85'), (86,'86'), (87,'87'), (88,'88'), (89,'89'), (90,'90'), (91,'91'), (92,'92'), (93,'93'), (94,'94'), (95,'95'), (96,'96'), (97,'97'), (98,'98'), (99,'99'), (100,'100'), (101,'101')
IcebergのBucket機能について
この後に、パーティション設定に利用するBucket機能について、事前に解説します。Bucket機能は、データのパーティショニングを効率的に行うための重要な機能です。Bucketは、ハッシュ関数を使用してデータを指定された数のバケットに分散させる方法です。
Bucketの特長
-
カーディナリティの高いカラムに適している
- ユニークな値が多いカラムに対して効果的です。
-
データの均等分散
- ハッシュ関数を使用することで、データを指定された数のバケットに均等に分散させます。
-
クエリパフォーマンスの向上
- 適切にバケッティングされたデータは、クエリの実行時間を短縮し、パフォーマンスを向上させます。
-
設定の簡易性
- テーブル作成時にPARTITIONED BY句で簡単に設定できます。
Bucketの使用例
以下はbucket関数を使用してテーブルを作成する例です。この例では、idカラムを16のバケットに分散させています。
CREATE TABLE iceberg_labo.test (
id int,
data string)
PARTITIONED BY (bucket(16,id))
LOCATION 's3://cm-datalake-20241026/test1/'
TBLPROPERTIES (
'table_type'='ICEBERG'
);
100パーティションの壁の挙動を把握する
Icebergテーブルフォーマットかつ、Athena Engine EngineV3で検証を進めます。
検証1: 100パーティション超えでエラーを確認
100パーティション超えでエラーになることを確認します。
-- DROP TABLE iceberg_labo.test1;
CREATE TABLE iceberg_labo.test1 (
id int,
data string
)
PARTITIONED BY (id)
LOCATION 's3://cm-datalake-20241026/test1/'
TBLPROPERTIES (
'table_type'='ICEBERG'
);
INSERT INTO iceberg_labo.test1
VALUES (1,'1'), (2,'2'), (3,'3'), (4,'4'), (5,'5'), (6,'6'), (7,'7'), (8,'8'), (9,'9'), (10,'10'), (11,'11'), (12,'12'), (13,'13'), (14,'14'), (15,'15'), (16,'16'), (17,'17'), (18,'18'), (19,'19'), (20,'20'), (21,'21'), (22,'22'), (23,'23'), (24,'24'), (25,'25'), (26,'26'), (27,'27'), (28,'28'), (29,'29'), (30,'30'), (31,'31'), (32,'32'), (33,'33'), (34,'34'), (35,'35'), (36,'36'), (37,'37'), (38,'38'), (39,'39'), (40,'40'), (41,'41'), (42,'42'), (43,'43'), (44,'44'), (45,'45'), (46,'46'), (47,'47'), (48,'48'), (49,'49'), (50,'50'), (51,'51'), (52,'52'), (53,'53'), (54,'54'), (55,'55'), (56,'56'), (57,'57'), (58,'58'), (59,'59'), (60,'60'), (61,'61'), (62,'62'), (63,'63'), (64,'64'), (65,'65'), (66,'66'), (67,'67'), (68,'68'), (69,'69'), (70,'70'), (71,'71'), (72,'72'), (73,'73'), (74,'74'), (75,'75'), (76,'76'), (77,'77'), (78,'78'), (79,'79'), (80,'80'), (81,'81'), (82,'82'), (83,'83'), (84,'84'), (85,'85'), (86,'86'), (87,'87'), (88,'88'), (89,'89'), (90,'90'), (91,'91'), (92,'92'), (93,'93'), (94,'94'), (95,'95'), (96,'96'), (97,'97'), (98,'98'), (99,'99'), (100,'100'), (101,'101');
100パーティション超えで、想定通りとエラーになりました。
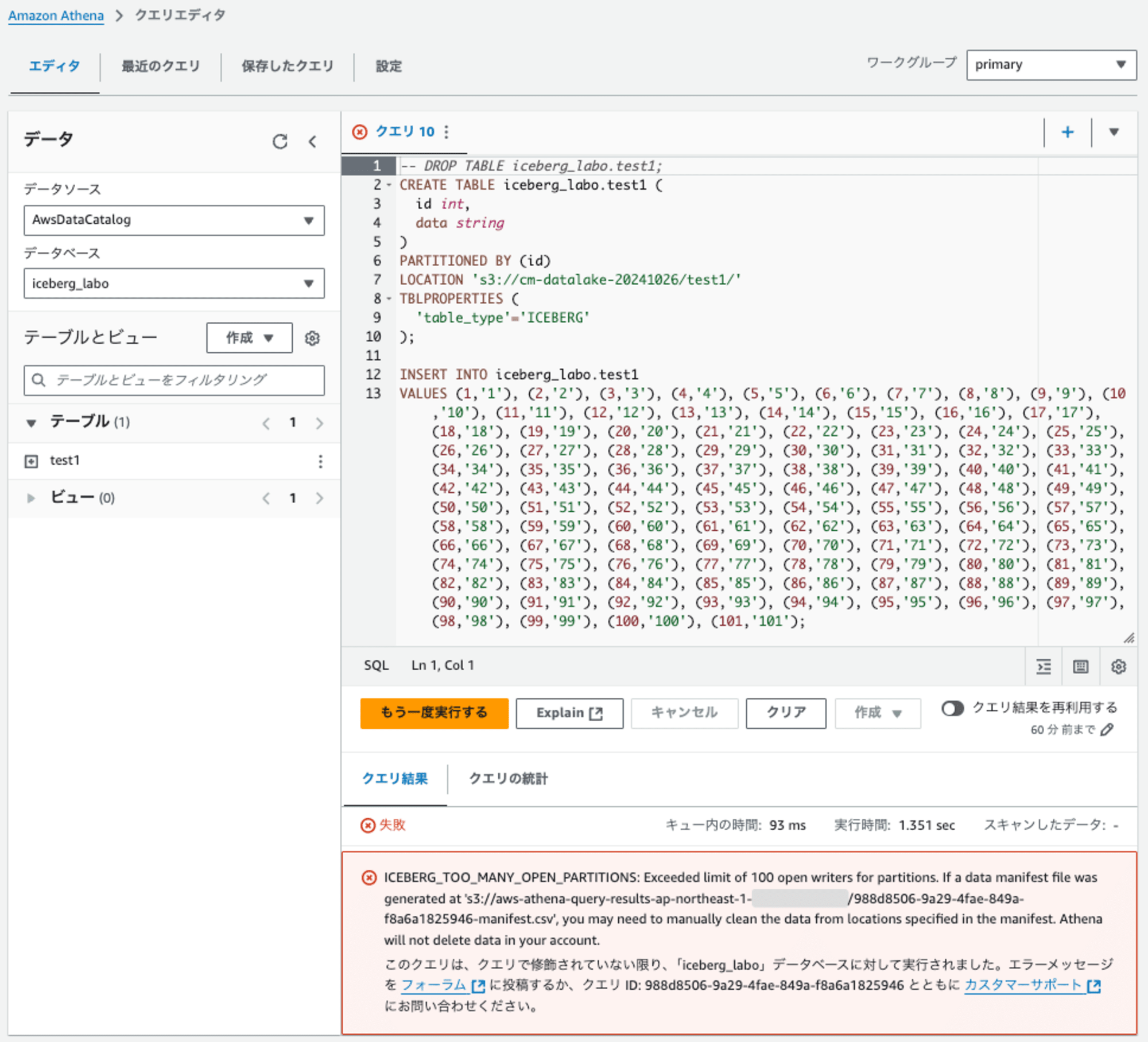
検証2: パーティション指定でBucketの数を101、101レコードをINSERT
パーティション指定でBucketの数を101に設定します。そのテーブルに101レコードをINSERTします。
-- DROP TABLE iceberg_labo.test2;
CREATE TABLE iceberg_labo.test2 (
id int,
data string
)
PARTITIONED BY (bucket(101,id))
LOCATION 's3://cm-datalake-20241026/test2/'
TBLPROPERTIES (
'table_type'='ICEBERG'
);
INSERT INTO iceberg_labo.test2
VALUES (1,'1'), (2,'2'), (3,'3'), (4,'4'), (5,'5'), (6,'6'), (7,'7'), (8,'8'), (9,'9'), (10,'10'), (11,'11'), (12,'12'), (13,'13'), (14,'14'), (15,'15'), (16,'16'), (17,'17'), (18,'18'), (19,'19'), (20,'20'), (21,'21'), (22,'22'), (23,'23'), (24,'24'), (25,'25'), (26,'26'), (27,'27'), (28,'28'), (29,'29'), (30,'30'), (31,'31'), (32,'32'), (33,'33'), (34,'34'), (35,'35'), (36,'36'), (37,'37'), (38,'38'), (39,'39'), (40,'40'), (41,'41'), (42,'42'), (43,'43'), (44,'44'), (45,'45'), (46,'46'), (47,'47'), (48,'48'), (49,'49'), (50,'50'), (51,'51'), (52,'52'), (53,'53'), (54,'54'), (55,'55'), (56,'56'), (57,'57'), (58,'58'), (59,'59'), (60,'60'), (61,'61'), (62,'62'), (63,'63'), (64,'64'), (65,'65'), (66,'66'), (67,'67'), (68,'68'), (69,'69'), (70,'70'), (71,'71'), (72,'72'), (73,'73'), (74,'74'), (75,'75'), (76,'76'), (77,'77'), (78,'78'), (79,'79'), (80,'80'), (81,'81'), (82,'82'), (83,'83'), (84,'84'), (85,'85'), (86,'86'), (87,'87'), (88,'88'), (89,'89'), (90,'90'), (91,'91'), (92,'92'), (93,'93'), (94,'94'), (95,'95'), (96,'96'), (97,'97'), (98,'98'), (99,'99'), (100,'100'), (101,'101');
101レコードをINSERTが成功しました。
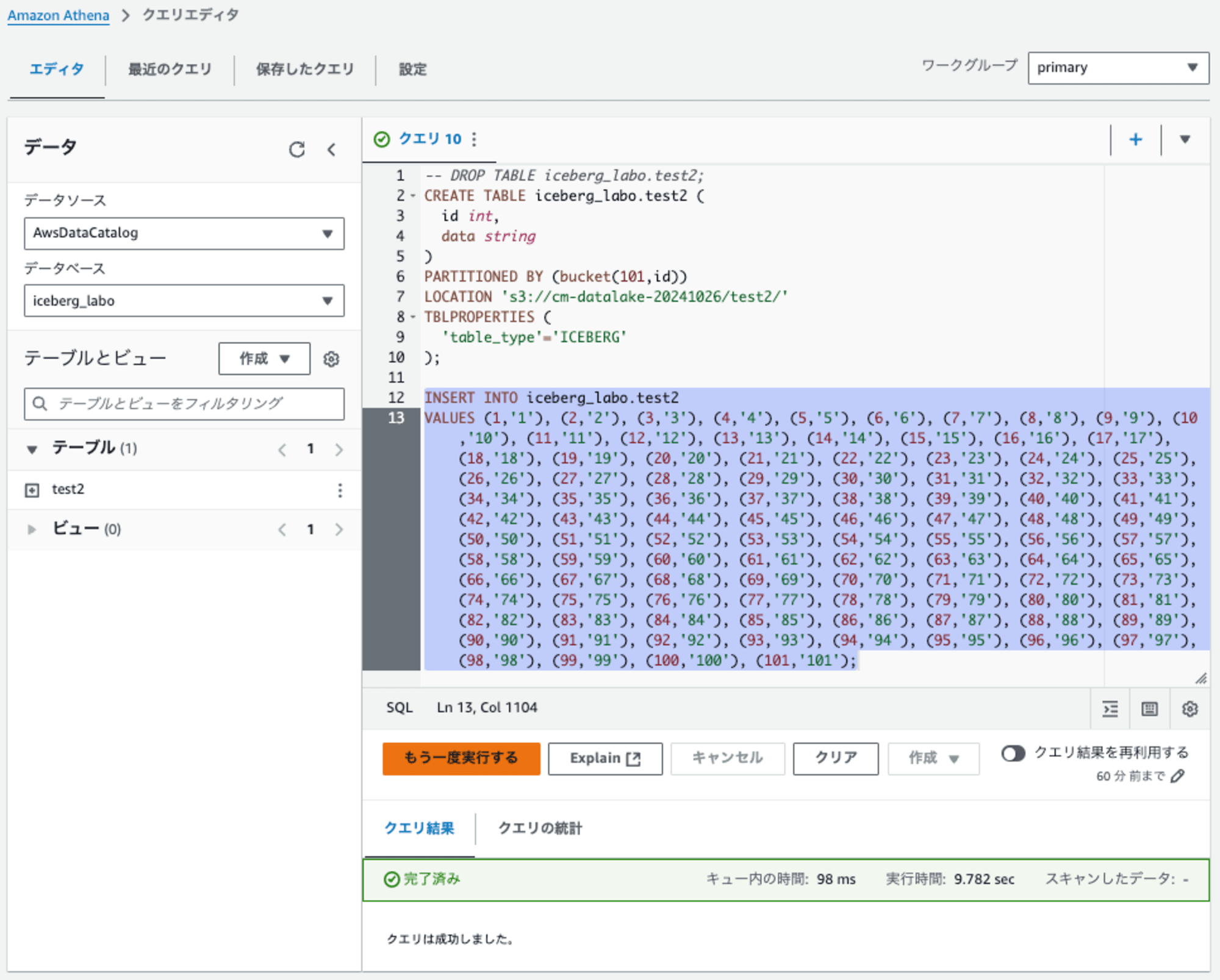
下記のようにdataフォルダ直下に64のハッシュのフォルダが作成されて、その下にデータが保存されています。
検証3: 検証2のパーティション指定に、パーティションキーdataを追加
検証2のパーティション指定に、パーティションキーdataを追加しました。そのテーブルに101レコードをINSERTします。
-- DROP TABLE iceberg_labo.test3;
CREATE TABLE iceberg_labo.test3 (
id int,
data string
)
PARTITIONED BY (bucket(101,id),data)
LOCATION 's3://cm-datalake-20241026/test3/'
TBLPROPERTIES (
'table_type'='ICEBERG'
);
INSERT INTO iceberg_labo.test3
VALUES (1,'1'), (2,'2'), (3,'3'), (4,'4'), (5,'5'), (6,'6'), (7,'7'), (8,'8'), (9,'9'), (10,'10'), (11,'11'), (12,'12'), (13,'13'), (14,'14'), (15,'15'), (16,'16'), (17,'17'), (18,'18'), (19,'19'), (20,'20'), (21,'21'), (22,'22'), (23,'23'), (24,'24'), (25,'25'), (26,'26'), (27,'27'), (28,'28'), (29,'29'), (30,'30'), (31,'31'), (32,'32'), (33,'33'), (34,'34'), (35,'35'), (36,'36'), (37,'37'), (38,'38'), (39,'39'), (40,'40'), (41,'41'), (42,'42'), (43,'43'), (44,'44'), (45,'45'), (46,'46'), (47,'47'), (48,'48'), (49,'49'), (50,'50'), (51,'51'), (52,'52'), (53,'53'), (54,'54'), (55,'55'), (56,'56'), (57,'57'), (58,'58'), (59,'59'), (60,'60'), (61,'61'), (62,'62'), (63,'63'), (64,'64'), (65,'65'), (66,'66'), (67,'67'), (68,'68'), (69,'69'), (70,'70'), (71,'71'), (72,'72'), (73,'73'), (74,'74'), (75,'75'), (76,'76'), (77,'77'), (78,'78'), (79,'79'), (80,'80'), (81,'81'), (82,'82'), (83,'83'), (84,'84'), (85,'85'), (86,'86'), (87,'87'), (88,'88'), (89,'89'), (90,'90'), (91,'91'), (92,'92'), (93,'93'), (94,'94'), (95,'95'), (96,'96'), (97,'97'), (98,'98'), (99,'99'), (100,'100'), (101,'101');
パーティション指定でBucketのきーと組み合わせても、100パーティション超えエラーになりました。
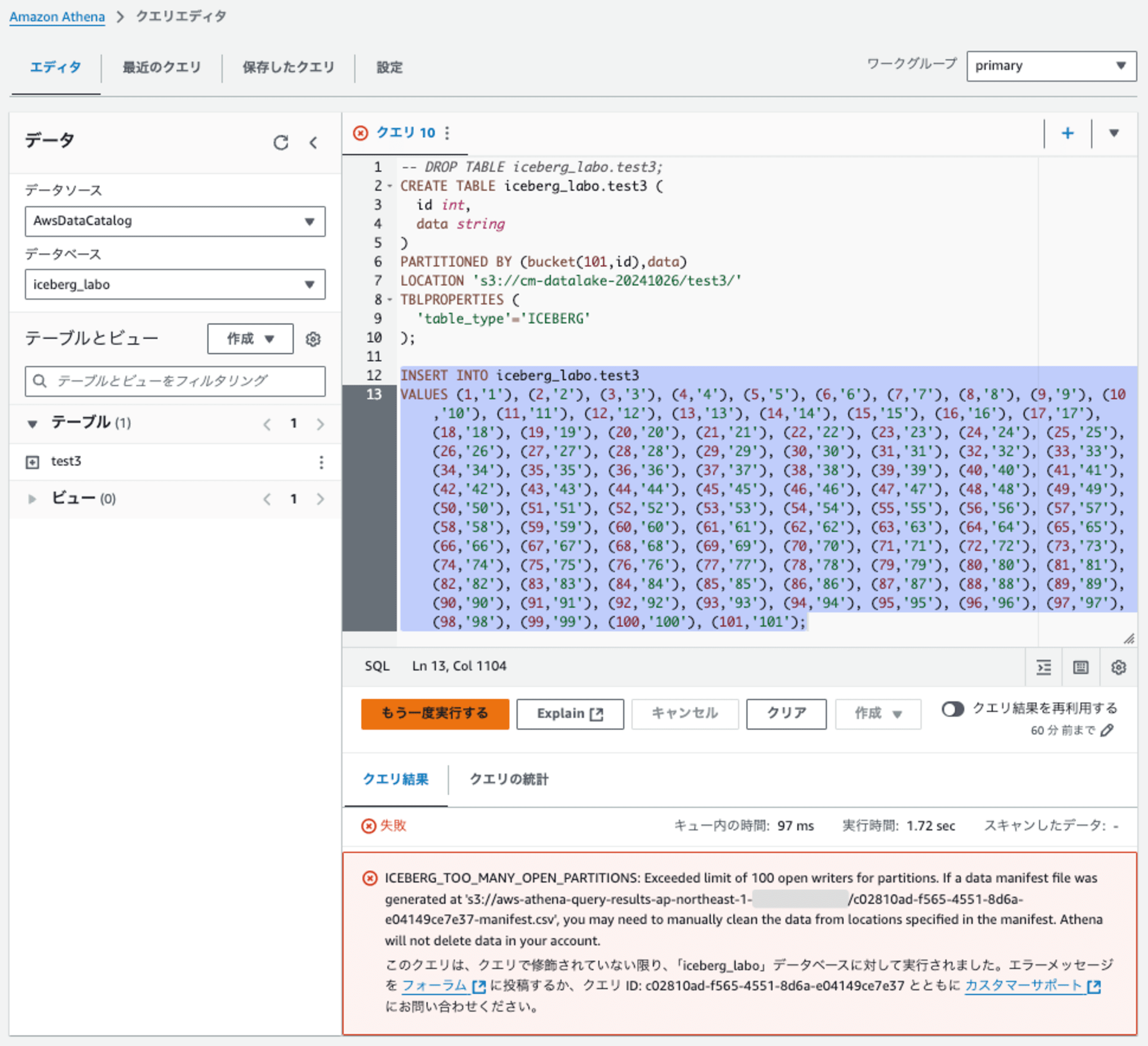
なお、PARTITIONED BY (bucket(101,id),bucket(101,data))も試しましたが同様にエラーでした。
検証4: パーティション指定でBucketの数を201、201レコードをINSERT
検証2が成功したので、パーティション指定でBucketの数を201に設定します。そのテーブルに201レコードをINSERTします。
-- DROP TABLE iceberg_labo.test4;
CREATE TABLE iceberg_labo.test4 (
id int,
data string
)
PARTITIONED BY (bucket(201,id))
LOCATION 's3://cm-datalake-20241026/test4/'
TBLPROPERTIES (
'table_type'='ICEBERG'
);
INSERT INTO iceberg_labo.test4
VALUES (1,'1'), (2,'2'), (3,'3'), (4,'4'), (5,'5'), (6,'6'), (7,'7'), (8,'8'), (9,'9'), (10,'10'), (11,'11'), (12,'12'), (13,'13'), (14,'14'), (15,'15'), (16,'16'), (17,'17'), (18,'18'), (19,'19'), (20,'20'), (21,'21'), (22,'22'), (23,'23'), (24,'24'), (25,'25'), (26,'26'), (27,'27'), (28,'28'), (29,'29'), (30,'30'), (31,'31'), (32,'32'), (33,'33'), (34,'34'), (35,'35'), (36,'36'), (37,'37'), (38,'38'), (39,'39'), (40,'40'), (41,'41'), (42,'42'), (43,'43'), (44,'44'), (45,'45'), (46,'46'), (47,'47'), (48,'48'), (49,'49'), (50,'50'), (51,'51'), (52,'52'), (53,'53'), (54,'54'), (55,'55'), (56,'56'), (57,'57'), (58,'58'), (59,'59'), (60,'60'), (61,'61'), (62,'62'), (63,'63'), (64,'64'), (65,'65'), (66,'66'), (67,'67'), (68,'68'), (69,'69'), (70,'70'), (71,'71'), (72,'72'), (73,'73'), (74,'74'), (75,'75'), (76,'76'), (77,'77'), (78,'78'), (79,'79'), (80,'80'), (81,'81'), (82,'82'), (83,'83'), (84,'84'), (85,'85'), (86,'86'), (87,'87'), (88,'88'), (89,'89'), (90,'90'), (91,'91'), (92,'92'), (93,'93'), (94,'94'), (95,'95'), (96,'96'), (97,'97'), (98,'98'), (99,'99'), (100,'100'), (101,'101'), (101,'101'), (102,'102'), (103,'103'), (104,'104'), (105,'105'), (106,'106'), (107,'107'), (108,'108'), (109,'109'), (110,'110'), (111,'111'), (112,'112'), (113,'113'), (114,'114'), (115,'115'), (116,'116'), (117,'117'), (118,'118'), (119,'119'), (120,'120'), (121,'121'), (122,'122'), (123,'123'), (124,'124'), (125,'125'), (126,'126'), (127,'127'), (128,'128'), (129,'129'), (130,'130'), (131,'131'), (132,'132'), (133,'133'), (134,'134'), (135,'135'), (136,'136'), (137,'137'), (138,'138'), (139,'139'), (140,'140'), (141,'141'), (142,'142'), (143,'143'), (144,'144'), (145,'145'), (146,'146'), (147,'147'), (148,'148'), (149,'149'), (150,'150'), (151,'151'), (152,'152'), (153,'153'), (154,'154'), (155,'155'), (156,'156'), (157,'157'), (158,'158'), (159,'159'), (160,'160'), (161,'161'), (162,'162'), (163,'163'), (164,'164'), (165,'165'), (166,'166'), (167,'167'), (168,'168'), (169,'169'), (170,'170'), (171,'171'), (172,'172'), (173,'173'), (174,'174'), (175,'175'), (176,'176'), (177,'177'), (178,'178'), (179,'179'), (180,'180'), (181,'181'), (182,'182'), (183,'183'), (184,'184'), (185,'185'), (186,'186'), (187,'187'), (188,'188'), (189,'189'), (190,'190'), (191,'191'), (192,'192'), (193,'193'), (194,'194'), (195,'195'), (196,'196'), (197,'197'), (198,'198'), (199,'199'), (200,'200'), (201,'201');
検証2と境界は同じはずなのですが、エラーになりました。
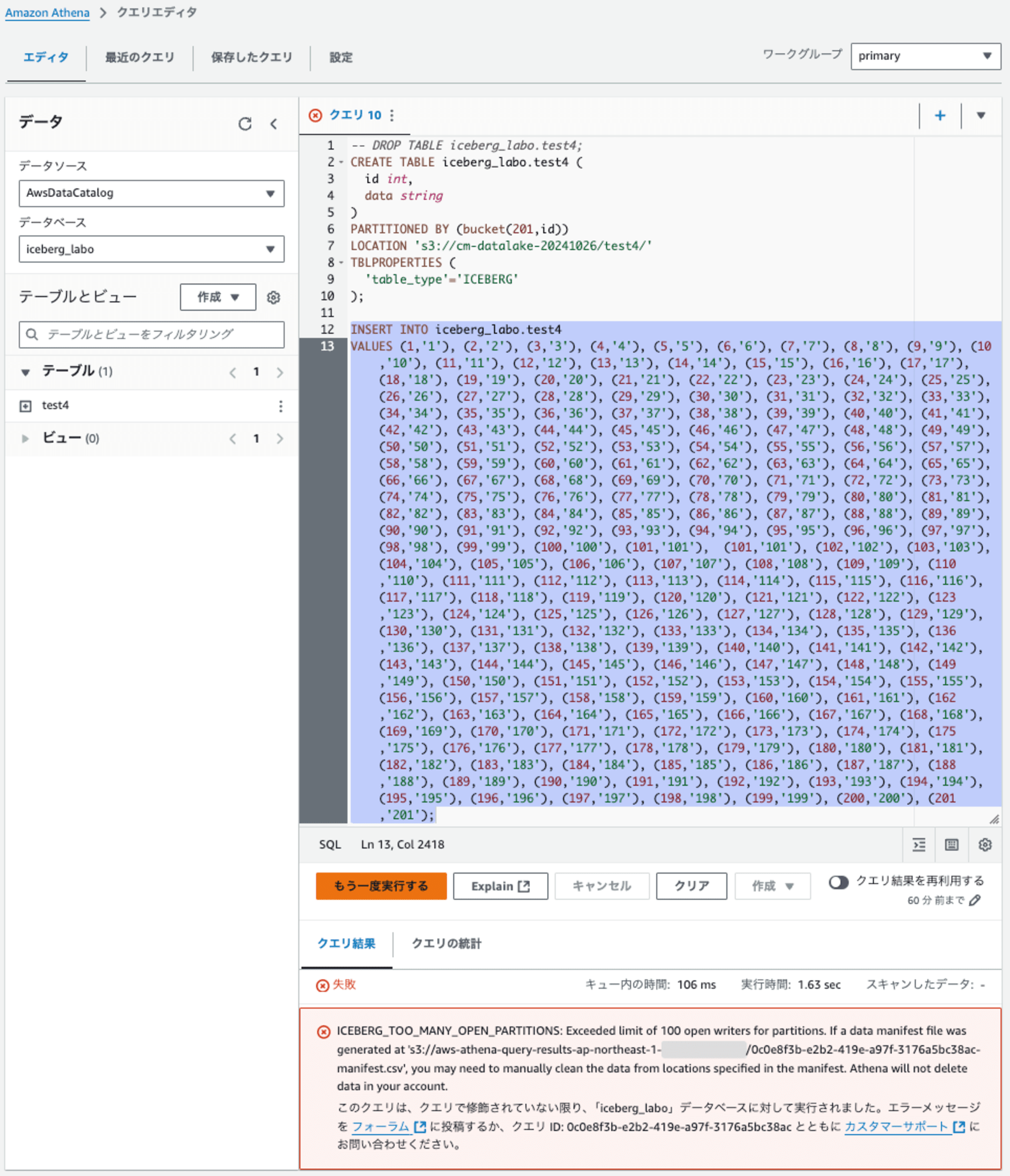
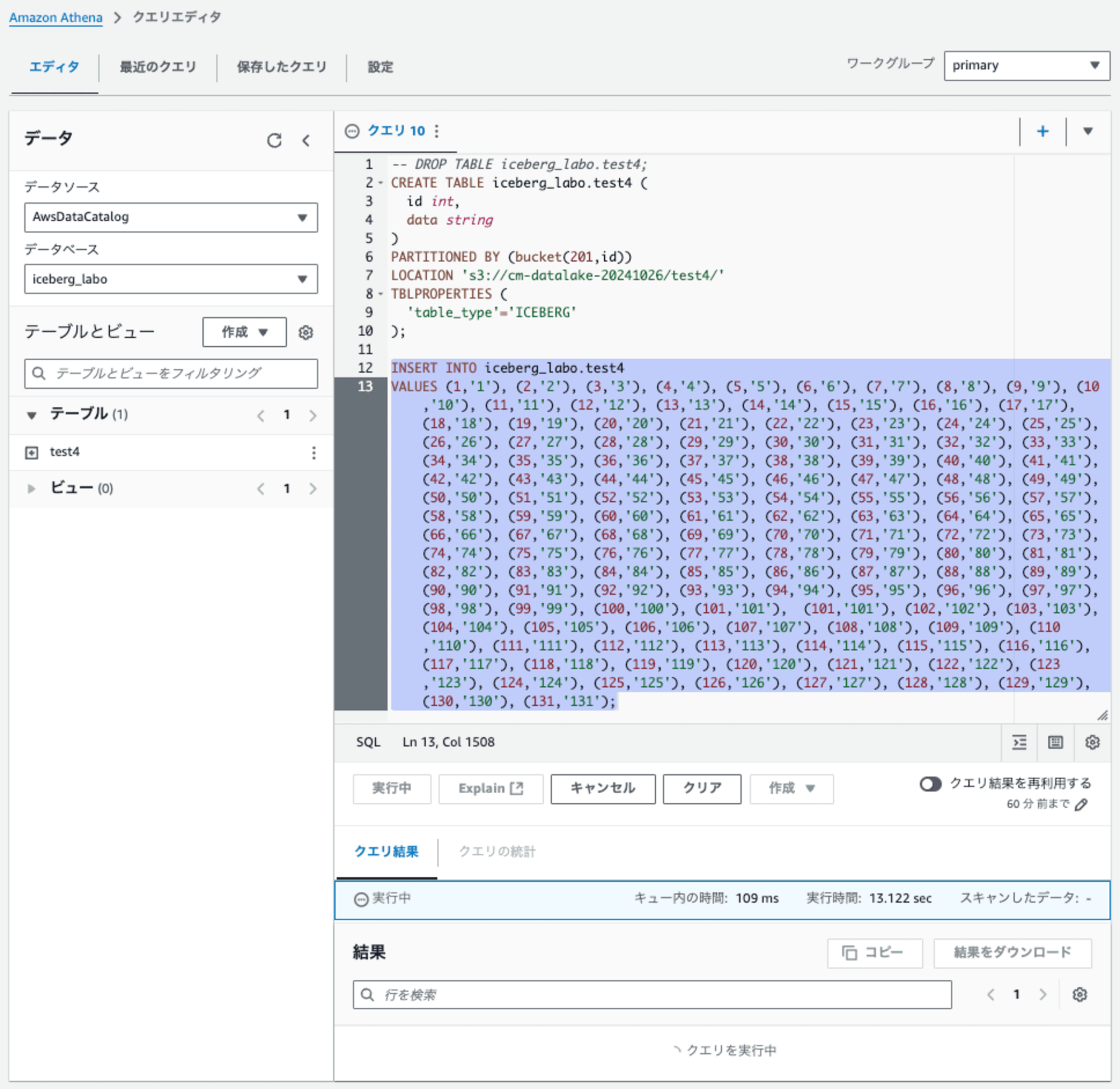
では、どこまでレコード数を減らせばできるのか?、、、試してみました。131レコードの時点で成功しました。なんか、中途半端なレコード数です。
下記のようにdataフォルダ直下に100のハッシュのフォルダが作成されて、その下にデータが保存されています。このあたり関連があるのかもしれませんね。
検証5: パーティション指定でBucketの数を100、201レコードをINSERT
検証1から検証4までの結果、わかったことをまとめます。
- bucketの指定は201でもエラーにならないため、テーブル作成の段階では問題にならない
- bucketの指定したテーブルに対して、100のハッシュフォルダまでデータをINSERTできた
上記の結果から、以下の仮説を立てた
- bucketの指定は100(正確には100以内)にすることで、100より多いハッシュフォルダが作成させるリスクを回避できる
よって、検証5では、bucketの指定は100のテーブルに対して、201レコードをINSERTできるかを確認する。
-- DROP TABLE iceberg_labo.test5;
CREATE TABLE iceberg_labo.test5 (
id int,
data string
)
PARTITIONED BY (bucket(100,id))
LOCATION 's3://cm-datalake-20241026/test5/'
TBLPROPERTIES (
'table_type'='ICEBERG'
);
INSERT INTO iceberg_labo.test5
VALUES (1,'1'), (2,'2'), (3,'3'), (4,'4'), (5,'5'), (6,'6'), (7,'7'), (8,'8'), (9,'9'), (10,'10'), (11,'11'), (12,'12'), (13,'13'), (14,'14'), (15,'15'), (16,'16'), (17,'17'), (18,'18'), (19,'19'), (20,'20'), (21,'21'), (22,'22'), (23,'23'), (24,'24'), (25,'25'), (26,'26'), (27,'27'), (28,'28'), (29,'29'), (30,'30'), (31,'31'), (32,'32'), (33,'33'), (34,'34'), (35,'35'), (36,'36'), (37,'37'), (38,'38'), (39,'39'), (40,'40'), (41,'41'), (42,'42'), (43,'43'), (44,'44'), (45,'45'), (46,'46'), (47,'47'), (48,'48'), (49,'49'), (50,'50'), (51,'51'), (52,'52'), (53,'53'), (54,'54'), (55,'55'), (56,'56'), (57,'57'), (58,'58'), (59,'59'), (60,'60'), (61,'61'), (62,'62'), (63,'63'), (64,'64'), (65,'65'), (66,'66'), (67,'67'), (68,'68'), (69,'69'), (70,'70'), (71,'71'), (72,'72'), (73,'73'), (74,'74'), (75,'75'), (76,'76'), (77,'77'), (78,'78'), (79,'79'), (80,'80'), (81,'81'), (82,'82'), (83,'83'), (84,'84'), (85,'85'), (86,'86'), (87,'87'), (88,'88'), (89,'89'), (90,'90'), (91,'91'), (92,'92'), (93,'93'), (94,'94'), (95,'95'), (96,'96'), (97,'97'), (98,'98'), (99,'99'), (100,'100'), (101,'101'), (101,'101'), (102,'102'), (103,'103'), (104,'104'), (105,'105'), (106,'106'), (107,'107'), (108,'108'), (109,'109'), (110,'110'), (111,'111'), (112,'112'), (113,'113'), (114,'114'), (115,'115'), (116,'116'), (117,'117'), (118,'118'), (119,'119'), (120,'120'), (121,'121'), (122,'122'), (123,'123'), (124,'124'), (125,'125'), (126,'126'), (127,'127'), (128,'128'), (129,'129'), (130,'130'), (131,'131'), (132,'132'), (133,'133'), (134,'134'), (135,'135'), (136,'136'), (137,'137'), (138,'138'), (139,'139'), (140,'140'), (141,'141'), (142,'142'), (143,'143'), (144,'144'), (145,'145'), (146,'146'), (147,'147'), (148,'148'), (149,'149'), (150,'150'), (151,'151'), (152,'152'), (153,'153'), (154,'154'), (155,'155'), (156,'156'), (157,'157'), (158,'158'), (159,'159'), (160,'160'), (161,'161'), (162,'162'), (163,'163'), (164,'164'), (165,'165'), (166,'166'), (167,'167'), (168,'168'), (169,'169'), (170,'170'), (171,'171'), (172,'172'), (173,'173'), (174,'174'), (175,'175'), (176,'176'), (177,'177'), (178,'178'), (179,'179'), (180,'180'), (181,'181'), (182,'182'), (183,'183'), (184,'184'), (185,'185'), (186,'186'), (187,'187'), (188,'188'), (189,'189'), (190,'190'), (191,'191'), (192,'192'), (193,'193'), (194,'194'), (195,'195'), (196,'196'), (197,'197'), (198,'198'), (199,'199'), (200,'200'), (201,'201');
201パーティションのレコードをINSERTが成功、101パーティションの壁を超えられました。
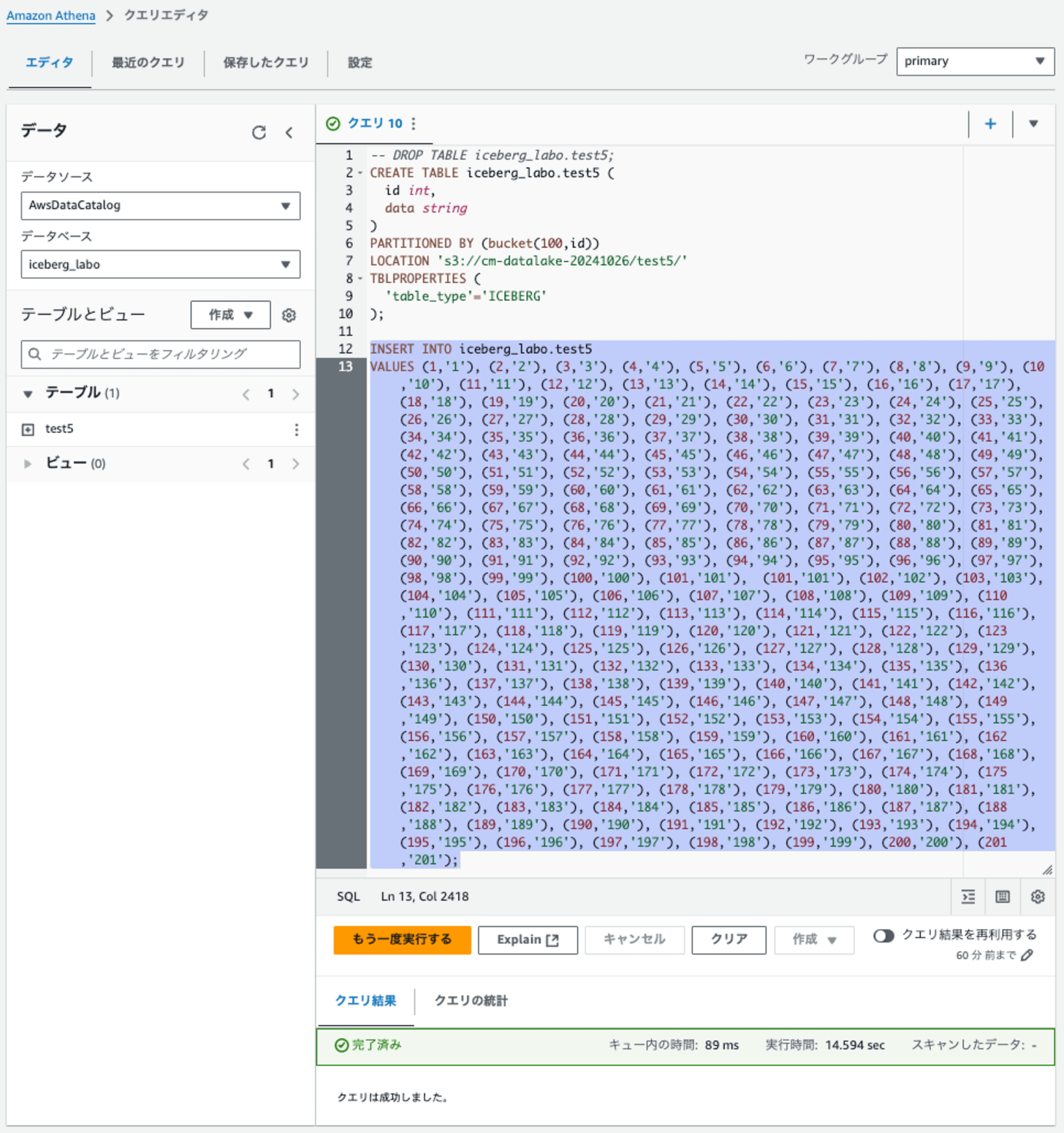
下記のようにdataフォルダ直下に84のハッシュフォルダが作成されていました。なお、上記のINSERTを数回実行したところ、同じハッシュフォルダの下にファイルが追加されるのではなく、ハッシュフォルダが追加されていました。
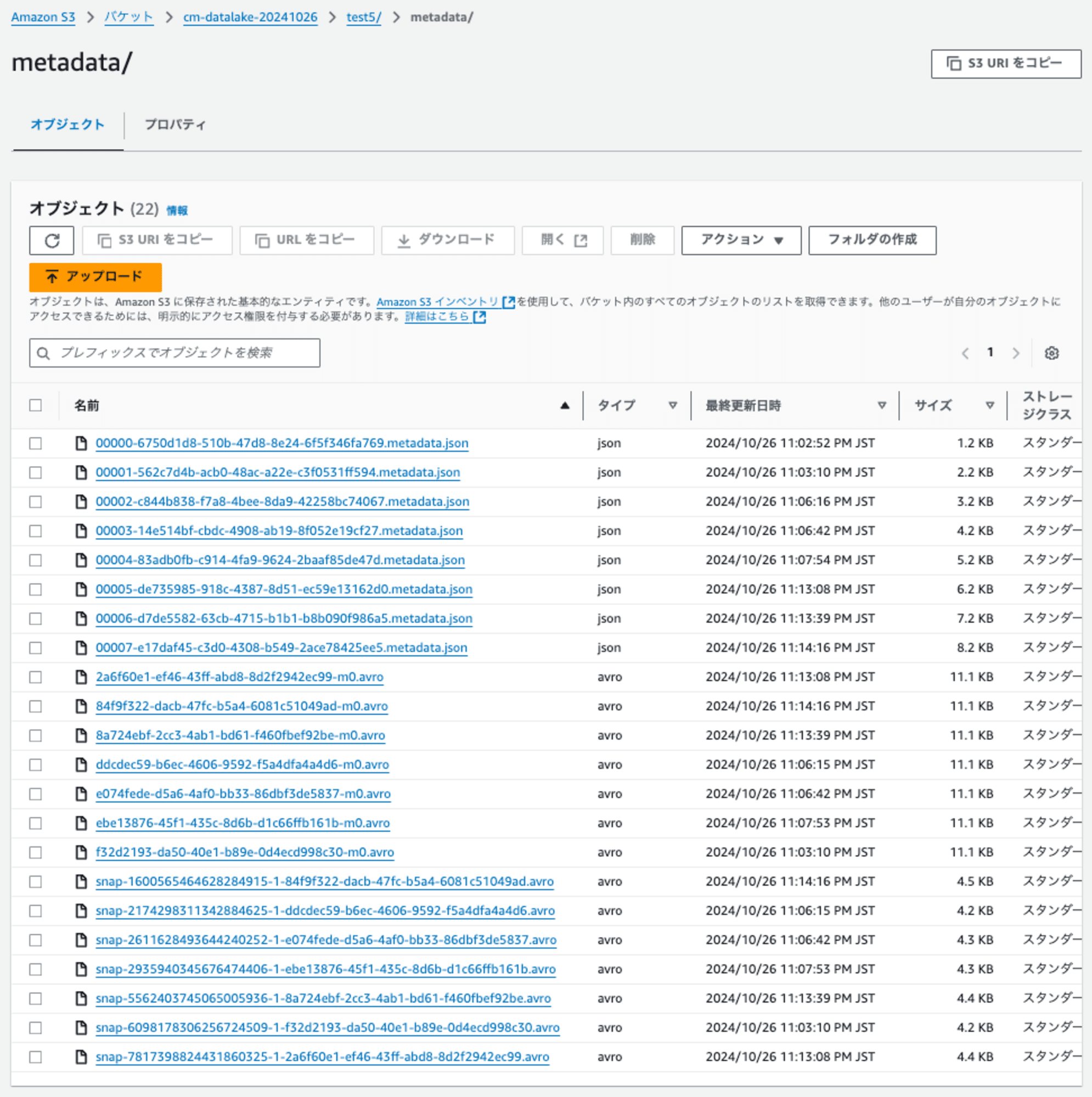
メタデータのファイル(.metadata.json)のファイルサイズが大きくなるのが気になります。OPTIMIZEやVACUUMを実施することで、100ハッシュファイルにコンパクションされるのではないかと予想しています。
結果
| 検証 | 条件 | 結果 | 実行時間 |
|---|---|---|---|
| 検証1 | 100パーティション超えでエラーを確認 | エラー(※1) | 1.351秒 |
| 検証2 | パーティション指定でBucketの数を101、101レコードをINSERT | クエリは成功しました。 | 9.782 秒 |
| 検証3 | 検証2のパーティション指定に、パーティションキーdataを追加 |
エラー(※1) | 1.72秒 |
| 検証4 | パーティション指定でBucketの数を201、201レコードをINSERT | エラー(※1) | 1.63 秒 |
| 検証5 | パーティション指定でBucketの数を100、201レコードをINSERT | クエリは成功しました。 | 14.594秒 |
※ エラー: ICEBERG_TOO_MANY_OPEN_PARTITIONS: Exceeded limit of 100 open writers for partitions.
最後に
検証結果から、Amazon Athena Icebergテーブルで100パーティションの壁を超える方法として、以下のことが明らかになりました。
-
パーティション指定でBucketの数を100に設定することで、100を超えるパーティションを持つデータの挿入が可能になります。
-
この方法を使用することで、201レコードのような100パーティションを超えるデータの挿入に成功しました。
-
ただし、この方法を使用すると処理時間が長くなる傾向があります。検証5では201レコードの挿入に14.594秒かかりました。
-
データはS3上で複数のハッシュフォルダに分散して保存されます。これにより、メタデータファイルのサイズが大きくなる可能性があります。
-
今後の課題として、OPTIMIZEやVACUUMの実行によるデータのコンパクション効果の検証が必要です。
この方法を使用することで、Amazon Athenaの100パーティション制限を回避できますが、パフォーマンスとストレージ効率のトレードオフを考慮する必要があります。実際の使用時には、データ量やクエリパターンに応じて適切に設計することが重要です。









